问题初现
近日做了一个缓存程序,大致处理流程如下图: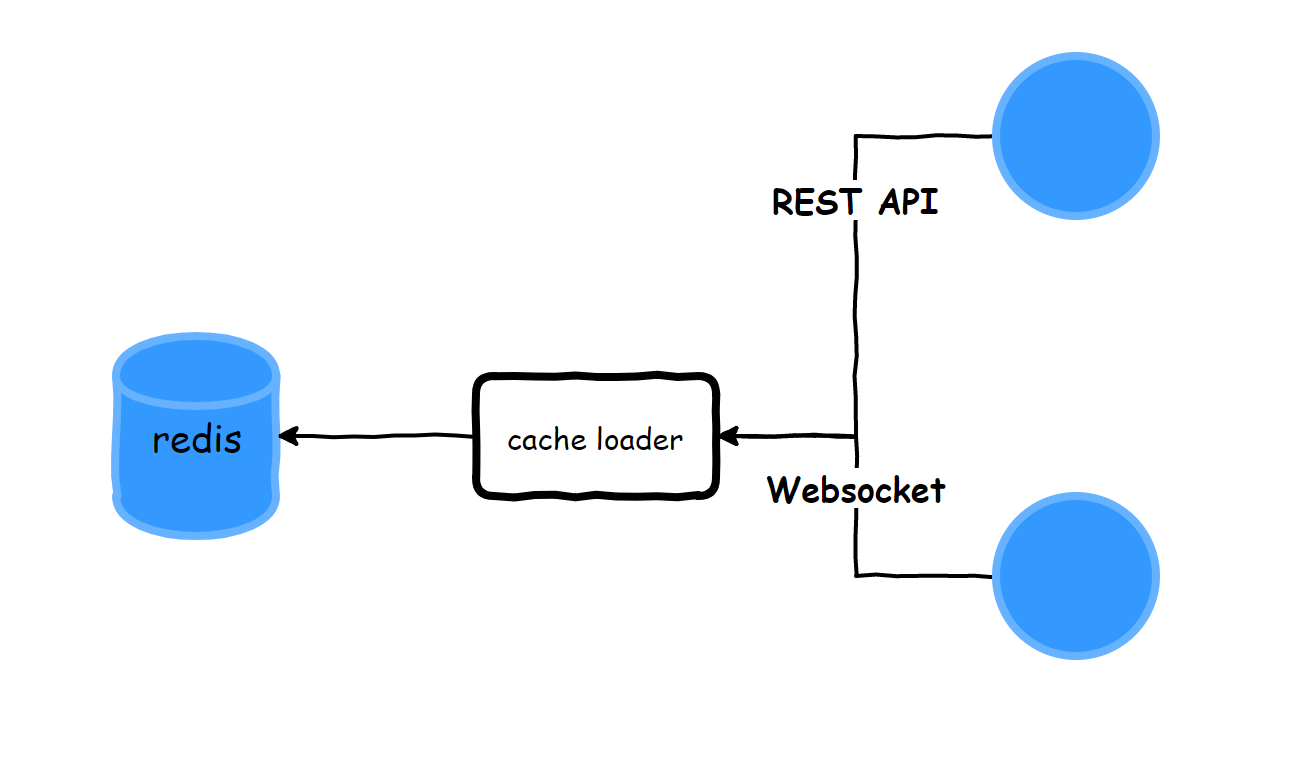
缓存按照主题大约分为4k个list,每个list都为2000个记录,总数据量约4G。
先通过REST请求获取数据,然后再通过websocket更新数据,同一个list中根据时间戳进行比较来进行插入最新的,删除最老的。
为了保证原子性,对于插入、删除采用lua脚本来执行。
预上线时发现cpu、内存飙升,并且将redis打到了30w的TPS,启动若干分钟后,因为JVM占用内存超过警戒线被OP监控kill掉。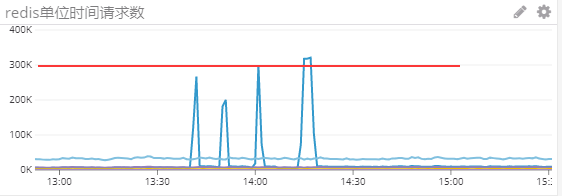
平滑处理
经过分析发现,在启动时,同时发起4k的请求,每个请求返回两千条数据,在单位时间内,大部分数据未写入redis之前堆积在JVM中。所以按照每100ms 10个REST请求做拆分,保证单位时间内的数据能够及时的插入redis,内部新建对象及时失效。
经过处理后,redis的TPS降到了5W,并且CPU、内存都恢复了正常预期。
减少连接和批量处理
由于redis是单线程处理,发现程序的redis client连接差不多有1k,这样会占用redis server的处理时间。
将redis client 精简为 200个。
原来的lua脚本每次处理一条数据,修改为可以传入List,然后在lua脚本中循环插入。
通过以上两步优化,redis的TPS降到了2.5W。
缓存加载
解决cpu、内存问题后,发现缓存的加载与预期不符,就是REST和websocket两者的返回会随机的加载入redis。
由于这两步都是异步操作,采用flag的方式来控制加载顺序。尝试修改后,还是不能解决顺序问题。
暴力解决
原来是希望能够在新旧版本接替时,还能够使用原来加载的缓存数据,但是由于旧版本被停止的时候对redis的处理可能影响到新版本的处理。所以直接在新版本加载REST的时候,在lua脚本中加上逻辑,先删除缓存,再插入2k条。
最终问题解决。
回顾总结
- 对于大量数据缓存加载,要注意单位时间加载数据量,防止出现性能突发瓶颈。
- redis client连接数多,并不一定能够增强性能。
- 缓存如果生效成本低,最好采用直接失效的方式来保证正确性,并且程序实现也可以减少复杂度。