介绍
hazelcast是一个开源的内存数据网格( In-Memory Data Grid (IMDG))。分为开源版和商用版,功能差异如下图: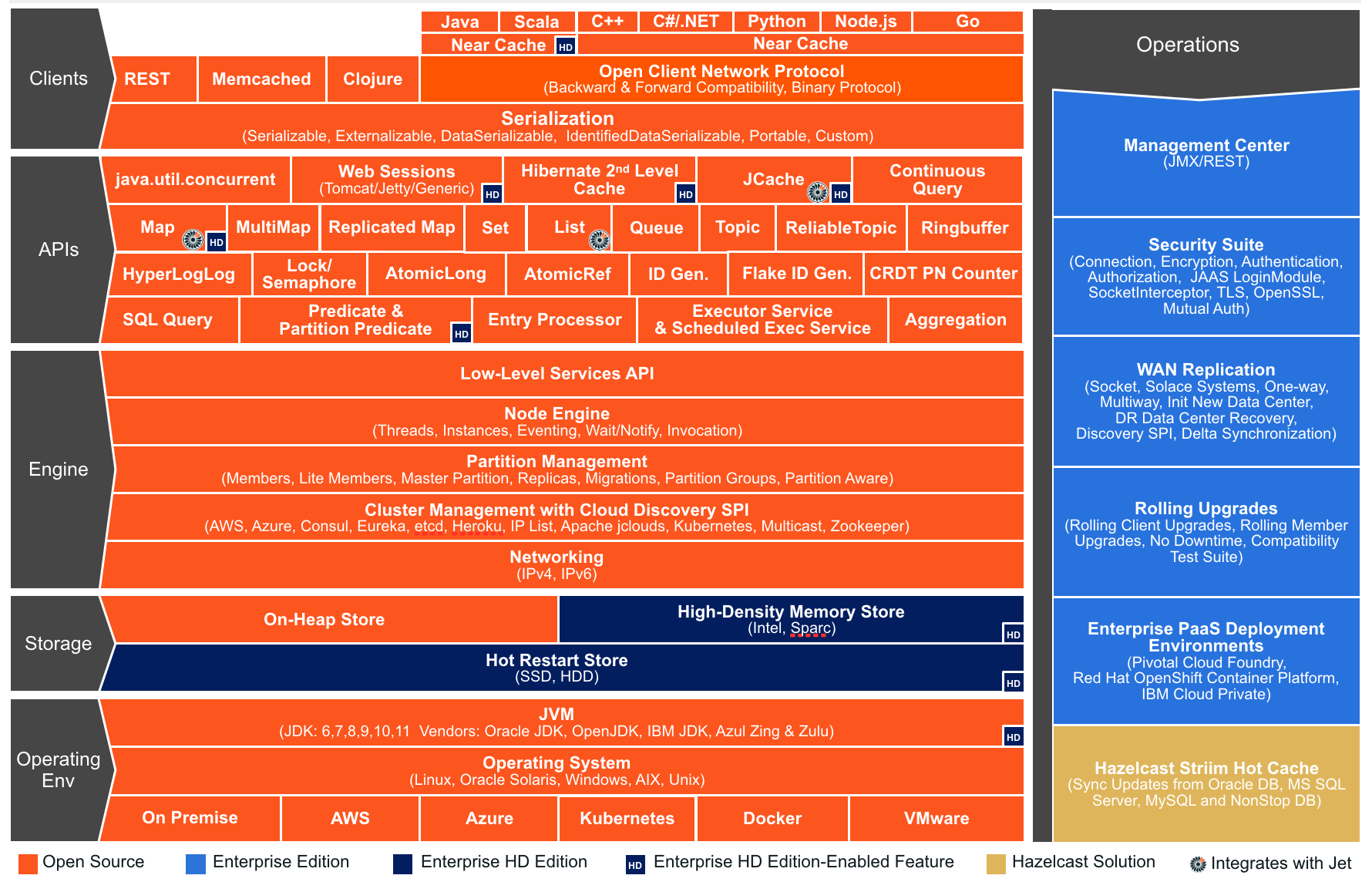
为什么用hazelcast?
hazelcast主要对标的是传统的数据持久化存储。
数据是软件系统的核心。在传统架构中,关系数据库仍然是存储、访问数据的首选。后来为了减轻数据库的压力,人们又引入了缓存、二级缓存等。但是缓存其实只解决了查询的压力,对于频繁写的场景其实无能为力。缓存本身也存在一致性的问题,就是缓存更改和失效的策略需要权衡。另外如果是多副本的缓存,对于多副本之间的同步机制也是比较头疼的一件事。
hazelcast是围绕分发概念设计的纯内存化的一种全新数据访问方法。具有弹性扩展、无主、完全内存化、提供开箱即用的分布式数据结构等优点。
hazelcast主要是通过内存化数据的方式,提供接近于标准java集合类操作的体验,并且有较好的分片、同步机制,构建了一个稳定的、弹性扩容的、分布式的内存数据网格。提升了数据的访问速度,通过多节点冗余降低了数据损失的风险。
官方推荐可以用在以下场景:
- 需要通过分区数据进行大数据处理的分析应用程序。
- 在网格中保留经常访问的数据。
- 缓存,尤其是支持开源JCache标准,具有弹性分布式可伸缩性。
- 内存式的K-V存储。
- 具有最高性能,可扩展性和低延迟的应用程序的主数据存储。
- 快速、可扩展的消息队列。
- 需要在分布式和云环境中弹性扩展的应用程序
- 适用于应用程序的高可用分布式缓存。